
线程池库Tpool实现笔记(1)
之前就想实现线程池来着,想看看里面有什么需要注意的地方。之前的Thread实现就是为这个做的准备。
我用C++实现了一个基于pthread的线程池。
项目地址:https://github.com/airekans/Tpool
什么是线程池?
顾名思义,线程池就是一个放着一堆线程在那跑着的对象。OO里面经常把这种存放着大量预分配资源的对象称之为池(Pool),比如线程池、数据库连接池、内存池。
为什么要用线程池?
那么我们为什么要用线程池呢?直接要用的时候就fork一个新的线程不是已经可以了么?
我们可以用下面这个场景来看看:
在HTTP服务器中,如果我们用单线程来处理请求的话,明显是不够的。为了提高服务器的并发性,我们利用线程来处理请求。
那么既然是用线程,假设我们用一个简单的来一个request,服务器就fork一个新的线程的方式,那么如果同时在1s内,服务器接收到1000个请求,那么服务器就需要fork 1000个线程来处理这些请求。1000个线程啊!!你能想象OS在这些线程之间切换的开销有多大么?而且光是创建和销毁线程也是有消耗的,如果请求和线程之间是1对1的话,这里系统的开销就会随着请求的增多的急剧增大。况且系统本身也是有线程数量的限制的,一个进程最多只能创建PTHREAD_THREADS_MAX这个多的线程。
线程池就是为了解决上面的问题,也就是减少处理请求从而新创建线程所造成的额外开销。如果我们在请求进来之前就fork好几个线程,而请求进来之后就交给这几个线程来处理,处理完之后这几个线程就继续等待下一个请求而不是结束执行。这样的方式就大大的减少了线程的创建、切换、销毁所带来的开销了。
除此之外,线程池还将各种线程之间的交互操作进行抽象,使得用户可以最大限度的不用担心多线程编程里面的繁琐的细节。
怎么实现线程池?
线程池的实现有很多种,不过基本都离不开下面的几个概念:
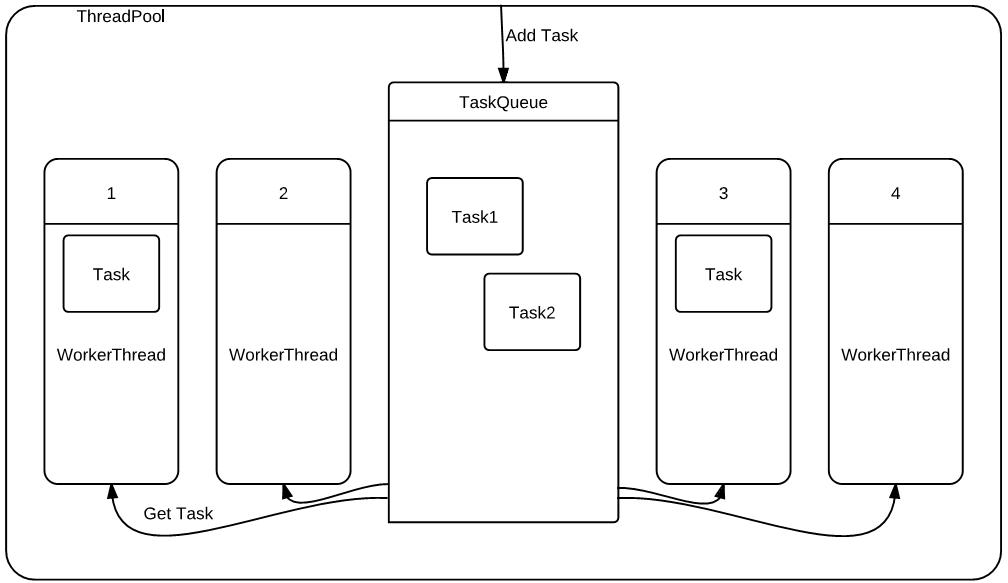
- 线程池(ThreadPool):总的对外接口,负责接收处理请求等工作。用户一般就只和这个接口打交道。
- 任务(Task):指需要进行的处理,比如上面的HTTP服务器例子的话就是处理HTTP请求返回对应的资源。一般用户会将这些请求交给线程池执行。
- 任务队列(TaskQueue):在线程池里面,需要存放用户提交过来的任务,以便让线程执行。一般来讲我们会用Queue来实现任务的存放,因为先进先出(FIFO)的方式是符合人们日常生活中处理请求的习惯的。
- 工作者线程(WorkerThread):负责处理请求的线程。由线程池负责管理,对于用户来说是不可见。工作者线程会从任务队列里面取出任务,然后执行任务。在执行完任务之后,会继续从任务队列里面取下一个任务。
上面的概念可以用下面的图来说明清楚:
有了上面的概念,我们可以大概的知道线程池的接口大致是下面这样:
1
2
3
4
5
6
7
class ThreadPool {
public:
ThreadPool(const size_t threadNum = 10);
bool AddTask(TaskBase::Ptr task);
void Stop();
};
其中ThreadPool的构造函数的参数是工作者线程数量。AddTask方法用来向线程池添加任务。Stop方法则是停止线程池的执行。
有了上面的接口,那么用户在使用的时候就只需要创建对应的Task,然后将他AddTask进线程池里面就可以不用关心任务的执行细节了。只需要知道这个任务会被异步的执行就可以了。

本作品由airekans创作,采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。
blog comments powered by Disqus